Uncovering GenAI - Chapter 4: Exploring Retrieval-Augmented Generation (RAG)
Posted on 2025-06-27
Retrieval Augmented Generation aka RAG is a new paradigm in the world of Generative AI which allows AI systems to provide more contextual, accurate and personalised responses by combining the power of LLM with rich and proprietary data sets. These data sets can range from internal documents, databases, to APIs and research papers. This approach uplifts the capabilities of LLMs from providing generic responses to delivering domain specific responses.
This blog post (fourth in the Uncovering GenAI series) picks apart the RAG paradigm, and dives deeper. It explains the basics and then moves to exploring what realistic RAG systems look like.
What is RAG and what are some real-world use cases?
The term "Retrieval Augmented Generation" (RAG) was coined in a 2020 paper
called "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks"
[1]. The paper introduced RAG as a new approach to be able
to enhance capabilities offered by pre-trained model.
The paper proposed the RAG solution to expand or revise the model's pre-trained memory. By default, the
pre-trained LLMs do not have access to any external memory, it is pretty much the memory of the model itself
which it learned during training i.e. parameterized implicit knowledge base. The expansion is done by
augmenting the model with non-parametric knowledge base i.e. retrieval based.
flowchart LR
U[User] --(1) prompts--> C[Chat
Application]
C --(2a) retrieves--> K[Proprietary
Knowledge Base]
K --(2b) relevant
information--> C
C --(3a) prompt +
knowledge --> L[Large Language
Model]
L --(3b) response --> C
C --(4) response --> U
[1] Diagram showing the RAG flow
The introduction of RAG approach led to number of fields to find application of GenAI in their domains. Here
are some examples you probably have come across in the last one or two years:
- Customer Support AI Assistants - Pretty much any popular website (ecommerce, banking, commercial software, etc.) has an AI powered chat assistant. These assistants tend to be very effective in answering customer queries as they have access to the company's up-to-date knowledge base such as FAQs, product manuals, and troubleshooting guides. Not only does such approach save many team member hours but also improves customer experience by answering queries quickly and accurately.
- Legal and Compliance - Law firms and compliance teams are using RAG to quickly search through large volumes of legal documents, contracts, and regulations. This helps them find relevant information, and identify risks.
- Content and Media summarization - Microsoft Teams, Atlassian, Vimeo and many other companies are using RAG to summarize meetings, videos, and other content. This helps users quickly catch up on important information without having to go through the entire content.
How does RAG work?
Before we dive into the process itself, we need to be aware of 3 key components simple RAG system is made of:
🔢 Embedding model
A pre-trained model that can convert input into a vector representation known as an embedding. Some popular embedding models are nomic-embed-text, mxbai-embed-large<, and all-minilm. You can explore some of these models on Ollama or Hugging Face.🗂️Vector Database
Vector databases are specialized databases designed to store text embeddings and retrieve them based on similarity. The similarity is calculated using a distance metric such as cosine metrics, dot product, etc. Examples: Qdrant, Pinecone, etc.💬 Chat Model
A pre-trained model that can generate response based on the input prompt. In the context of RAG, the input prompt is augmented with the relevant information retrieved from the vector database. Examples: OpenAI's GPT-3.5, Google's Gemini, Meta's Llama, etc.
With the above components in mind, we can now look at the key phases of a RAG system - Indexing and
Retrieval. Indexing phase aka preparation is all about building the
non-parametric knowledge base, while the Retrieval phase aka responding
combines the power of the non-parametric knowledge base with the pre-trained LLM to generate
relevant and contextual responses.
1. Indexing: Building the index -
The primary purpose of the phase is converting the proprietary knowledge base into embeddings using
the embedding model and then storing them in the vector database. Depending on the size of the data,
either the data is directly converted into embeddings or it is chunked into smaller pieces and then
converted. The indexing phase has to be done at the start, and as the knowledge base is updated
mechanisms to keep the index up-to-date are also required.
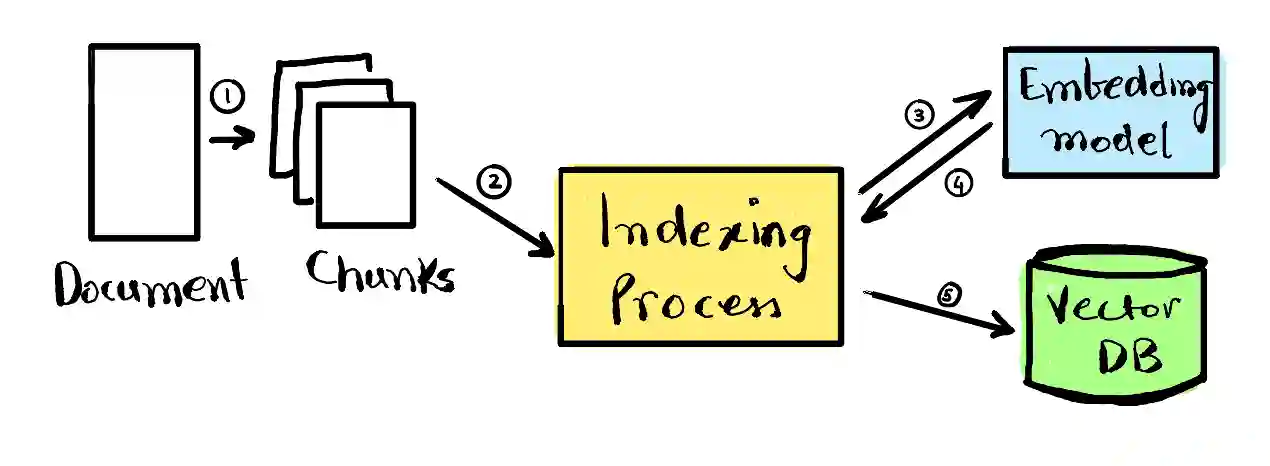 [2] Indexing Phase
[2] Indexing Phase
2. Retrieval: Responding to user prompt/input -
Provided the indexing phase is done, when the user prompts the chat application, the application
first retrieves the relevant information from the vector database. To do so it converts the user's
prompt into embeddings and then uses the search capabilities of the vector database to find top-K
relevant pieces of information. Once retrieval is done, the chat application then creates a new
prompt by combining the user's prompt with the retrieved information. Additionally, some guidance
can also be provided in the prompt to the chat model to help it generate expected response for the
user.
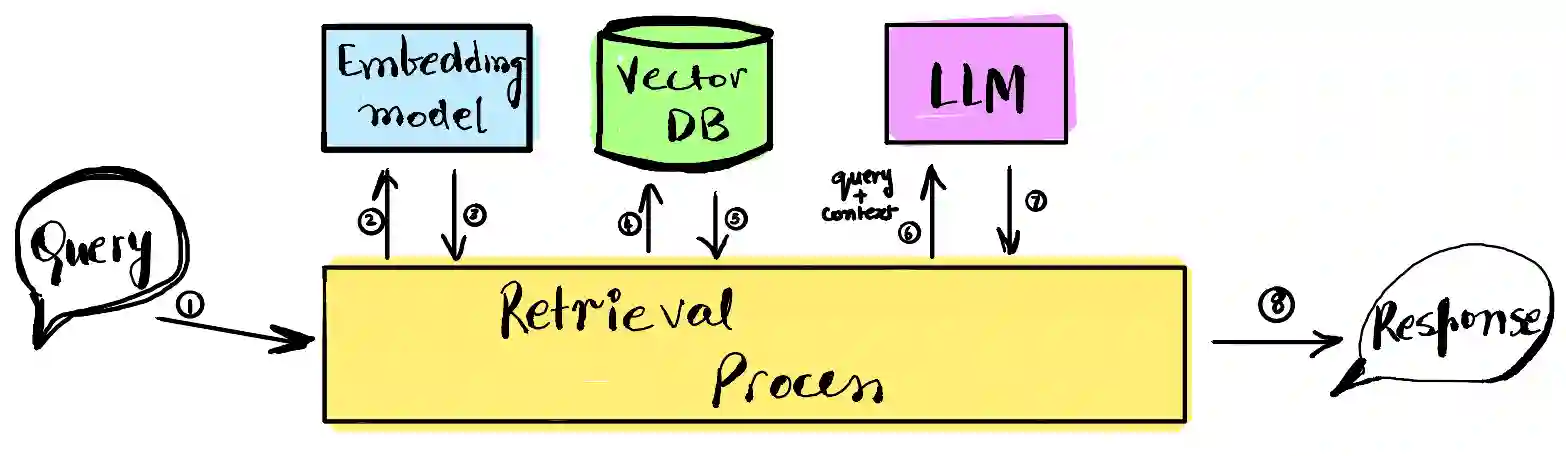 [3] Retrieval Phase
[3] Retrieval Phase
sequenceDiagram
actor U as User
box RAG Based Chat Application
participant ChatApp as Chat
Application
participant EmbeddingModel as Embedding
Model
participant VectorDB as Vector
Database
participant ChatModel as Chat
Model
end
Note over ChatApp: Phase 1 Indexing/Preparation
autonumber 1
ChatApp->>ChatApp: Get Proprietary Knowledge Base
opt For Large Documents
ChatApp->>ChatApp: Chunk documents into smaller pieces
end
ChatApp->>EmbeddingModel: Convert Knowledge
Base to Embeddings
EmbeddingModel-->>ChatApp: Return Embeddings
ChatApp->>VectorDB: Store Embeddings
Note over ChatApp: Phase 2 Retrieval/Responding
autonumber 1
U->>ChatApp: User Prompt
ChatApp->>EmbeddingModel: Convert User Prompt
to Embeddings
EmbeddingModel-->>ChatApp: Return Embeddings
ChatApp->>VectorDB: Search for Relevant Information
VectorDB-->>ChatApp: Return Top-K Relevant Information
ChatApp->>ChatModel: Combine User Prompt
and Relevant Information
ChatModel-->>ChatApp: Return Response
ChatApp-->>U: Return Response
[4] Sequence diagram showing the RAG flow
What are some practical considerations?
On paper we can say this sounds absolutely amazing, but in reality when building a RAG system, there are some
more nuances to consider. Knowing these nuances can help us build a more realistic RAG system. Let us dive into
some of these considerations and explore mitigations to them:
-
Building a good indexIn sequence diagram above, in phase 2 "Retrieval" the application retrieves the top-K relevant (step 2-5). The embedding of the user's prompt is used to search the vector database for the relevant information. If the quality of reterived information is not good, the response generated by the LLM will not be good either. There are multiple factors that go into building a good index:
- Choosing the right embedding model. While choosing an embedding model with more parameters can dimensions can mean more context it also implies more complexity and efficiency issues. The RAG application we are building should help us choose the right embedding model.
- Quality of knowledge base. "Garbage in, garbage out" is applicable here as well. We need to ensure data ingested is structured for best indexing outcome. When structuring data there are certain aspects to consider: cleansing data, redacting sensitive information, and handling errors for edge cases such as missing fields.
- Chunking the data into smaller pieces. The chunk size and strategy can have a significant impact in the quality of index and in turn the top-K relevant information retrieved. Chunking is a significant topic in iteself. I do plan to cover this in a following post with examples for now this post from Pinecone is a great starting point).
-
Formating the outputLLMs are designed to generate original human-like content. A simple way to get the Retrieval phase to output in the desired format is to provide a desired format to the constructed prompt as a guardrail (step 6 in sequence diagram under Phase 2: "Retrieval") to the LLM and let it generate the desired response. This approach is not always effective, it is rather a hit-and-miss. LLMs may not support a structure format out of the box leading to this hit or miss situation. Many LLMs support structured output formats and will yield consistent structured output when configured.
-
Ingestion scalabilityThe index would be created at the start, and as the knowledge base updates the index would need to be updated as well. There are two key things to consider here:
- The requirement of data freshness should help define a strategy of indexing. There are scenarios were we want index to reflect the latest data, and there are scenarios where we can afford a batch update approach.
- Deletion of stale data must be accounted for. If invalid or outdated data is not removed, the retrieval phase can generate context which would lead to incorrect responses.
-
HallucinationWhen the required information is missing and hence the vector database returns irrelevant data, the LLM's response may come across as a hallucination. This could be mitigated by establishing Guardrails. Guardrails can be established to re-write the user's input itself. Another set of guardrails can be established in the constructed prompt to the LLM to get it verify the retrieved information before generating a response.
Depending on the scenario, the challenges may differ and so will the mitigations. The above are some more
generic considerations that can be applied to most RAG systems. When working with a RAG system, it is helpful to
have a checklist of considerations established and continuing to fine-tune the system one step at a time.
A Practical RAG Solution
The more vanilla or so to say the simple RAG solution has been since its discovery been modified to address some
of these considerations. The next 2 iterations which are more realistic RAG solutions are:
Advanced RAG
The advanced RAG solution employs pre-retrieval and post-retrieval steps to improve the quality of
final response. Here is a set of pre and post retrieval option(s) it augments the simple RAG with:
-
Pre-retrieval: The focus of pre-retrieval is to help the system understand and expand the
user's query to improve the chances of finding the right information.
- Query-Routing: Based on varying queries, routing them to the optimal pathway for the query to b answered i.e the system decides which knowledge source, index, or database to query based on the type or intent of the user’s question.
- Query-Rewriting: Re-writing the user query to optimize it for retrieval. A variation of this is to create a few different queries e.g. concise, and a detailed query and then retrieve information for both queries.
- Query-Expansion: Similar to query-rewriting, but instead of re-writing the query, it builds on the existing query either by adding synonyms or related terms or creating a variation with the synonyms or related terms.
-
Post-retrieval: By employing post-retrieval steps, it helps improve the quality and
relevance of the final answer by process of selecting, refining, and/or combining retrieved
content.
- Re-ranking: Re-ranking the retrieved information to relocate the most relevant content to the edges of the prompt helps the LLM to generate a more accurate outcomes. This is done sometimes using another LLM or a custom scoring algorithm, so the best results are considered first.
- Summary: The results are synthesized or summarized before being passed to the LLM or included in the final response, helping to distill the key information.
- Fusion: Combining the results from multiple retrievals or sources to create a more complete and comprehensive response.
Modular RAG
Modular RAG offers more flexibility and extensibility as compared to the simple vanilla RAG and the advanced
RAG. By using modules and patterns as building blocks, it allows for innovations like restructured RAG
modules and rearranged RAG pipelines. The modular RAG solution uses existing modules such as re-writing,
re-ranking, summarization, etc as well as introduces some new modules and patterns such as:
- Search Module: This enables keyword/direct searches across various data source which expands on just similarity-search offered by vector database. A combination of the two types of searches can provide more relevant results.
- Memory Module: The module stores and retrieves relevant conversational or contextual history to inform the RAG system’s current response.
- Predict module: The Predict module aims to reduce redundancy and noise by generating context directly through the LLM, ensuring relevance and accuracy[2]. Instead of just passing all retrieved content to the user, the Predict module uses the LLM to synthesize and summarize only what truly matters, reducing clutter and improving response quality.
- Task Adapter Module: This modules allows the RAG system to adapt to different tasks. It does this by recognizing the task at hand and then selecting the appropriate modules and patterns to use.
- Rewrite-Retrieve-Read Pattern: The pattern is a sequence of steps starting with rewriting the user query, then retrieving relevant information, and finally reading the retrieved information to generate a response.
- Demonstrate-Search-Predict Pattern: This pattern involves demonstrating the task to the LLM, search augments with up-to-date information, and finally AI does its magic to predict the best response augments with the previous steps.
The paper "Retrieval-Augmented Generation for Large Language Models: A
Survey" helps lay a landscape of RAG techniques. The diagram is a great illustration showing the
above-mentioned practical RAG solutions.
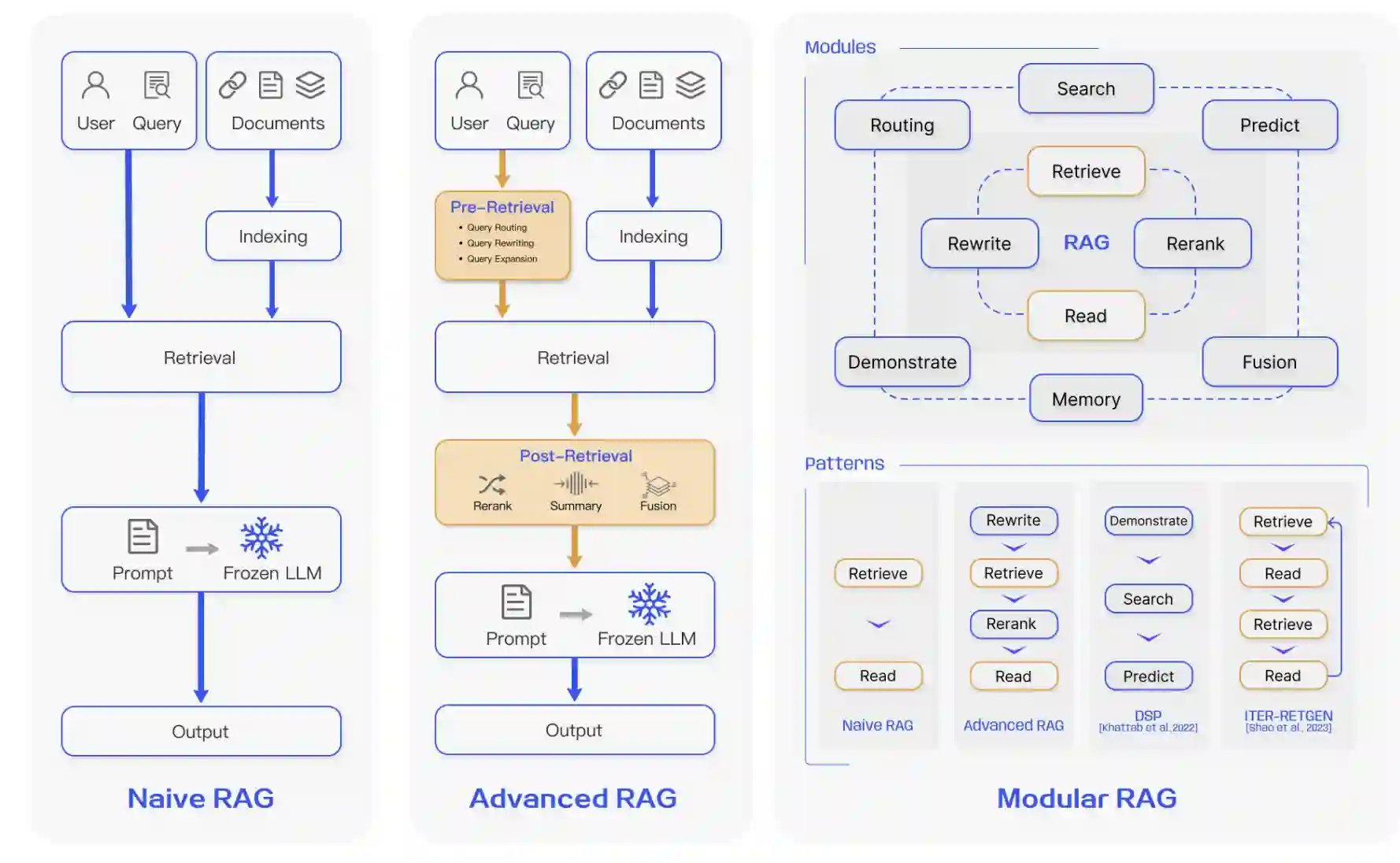
[5] Landscape of RAG techniques from
Retrieval-Augmented Generation for Large Language Models: A Survey
What's up next?
❯❯❯❯ In the following post Uncovering GenAI -
Chapter 5: Building a Retrieval-Augmented Generation Application, we will build a simple vanilla RAG
systems to get some hands-on experience.
Checkout the Uncovering GenAI series for previous and following posts in this
series.
References