Uncovering GenAI - Chapter 1: The Foundations
Posted on 2025-05-21
Many products are actively finding innovative use-cases for helping their customer base with Generative AI aka
GenAI. As software engineers and architects, we are tasked to build the applications and integrations which sit
behind the scenes powering these GenAI use-cases. A core belief that guides this approach is that establishing a
well-formed understanding of a technology before integration helps to uncover its maximum benefit. For those
working on a similar belief or in general like to go down the rabbit-hole, this blog is the first of the series
to uncover the basics of GenAI (i.e., remove the "buzz" from the buzzwords).
What is Intelligence, and Artificial Intelligence (AI)?
Intelligence is one's ability to learn from experience and to adapt to, shape, and select
environments[1]. While intelligence as a subject has
intrigued great minds and has been widely studied, the common denominator of many of the studies tend to
agree that intelligence involves mental abilities such as logic, reasoning, problem-solving,
decision-making, etc. Simply put, Artificial Intelligence is a field in computer science focused on
replicating human intelligence, specifically, the mental capabilities outlined above. The field studies and
wants to create systems which can become aware of situations and environments, then use their artificial
(i.e., human-made or synthetic) intelligence to achieve a desired goal.
Artificial Intelligence itself has some core fields of study – Expert Systems, Machine Learning, Robotics,
Natural language processing, and Computer Vision. Many of these fields of study originated between the 1940s and
1960s. Between then and now many advancements have been made. Many projects we tend to see as a result often
blend these areas. The Tesla Model 3D Park Assist combines the best of Computer Vision and Robotics (powered
by an occupancy network behind the scenes), showcasing the synergy of both technologies. Household devices like
Alexa and Google Home rely on Natural Language Processing (NLP) and Expert Systems to complete tasks through
voice commands and contextual understanding.
Machine Learning to Deep Learning to GenAI?
Machine Learning is a field in AI which focuses on learning from a large
set of data to autonomously perform a task at hand. Most of the early implementations of ML were based on
reinforcement learning techniques where humans were the reinforcement agents.
In the 1980s this changed with practical implementation of
Artificial Neural Networks (aka ANN) architectures. These architectures
transformed an input through many layers to a desired output. These layers, mimicking the interconnected human
neural networks, are trained on huge data-sets and then are adjusted and re-adjusted through the course of time
they are used based on its experience. Due to the layered nature of this architectural pattern it formed a
subfield in ML referred to as Deep Learning (where "deep" re-presents
the layered nature itself).
One of the popular ANNs was Recurrent Neural Network (aka RNN). RNNs are
known for processing sequential data leveraging their memory to maintain context (internal state) as input gets
transformed through their layer to produce an output. RNNs were quite a breakthrough, though the following
limitations kept it from reaching mass adoption:
- Long sequences bring their own challenges with this model. Memory limitations can impact maintaining an internal state as a sequence follows through the layers.
- Sequential processing is another key bottleneck. You cannot just throw GPUs and hope you can train it faster. This implies the cost and time of training both on the higher end. Additionally, it also implies slower response times to users.
"Attention Is All You Need"[2] was
a paper published in 2017 addressed the concerns stated above and introduced the
Transformer Model. We will look at how it did so briefly but with significantly
more parallelisation and GPUs at one's disposal the floodgates were ready to be opened.
The Boom!
Large Language Models came into picture based on these transformer models. These LLMs were trained on large
volumes of data enabling them to represent semantic relationships within words, and hence enabling them to
generate sequences of texts (sentences and paragraphs) which simply put "makes sense." These LLMs led to the
boom and mass adoption of Generative Artificial Intelligence.
Generative Artificial Intelligence or GenAI is the most rapidly evolving field in recent years that focuses
primarily in generating original content as output in form of text, images, audio, videos, 3D models, code, etc.
Now just to be clear GenAI was NOT a new field created post the popularity of transformer architecture. There
are other historical programs. AARON, a computer program created by Harold Coen[2] is well known for its
generated artwork and was conceived back in 1973. Transformer models just made sustainable scalability possible
due to lower cost, the ability to train and retrain on the latest data, and better context retention. Hence, as
mentioned earlier, this helps lower the barrier for mass adoption.
The authors of “Attention Is All You Need” as a proof of concept trained their transformer-based AI model with
Wikipedia articles and then used it to generate fictitious Wikipedia articles. The created content despite some
inconsistencies appeared to be very convincing and extremely detailed.
Key concepts in LLMs
For LLMs to work they need three key capabilities - read, understand and remember:
-
Tokenisation
For the purpose of unlocking the reading capability, a process called tokenisation is used. This process breaks down text into known words referred to as tokens. These tokens are then mapped to a TokenID which the model uses in turn.
You can play around with the Hugging Face tokeniser playground to get an understanding of how LLMs tokenise. -
Embeddings
To form understanding, LLMs need to establish relationship and context between words used in text. An embedding is a numerical representation of an information. The representation captures the semantic meaning of this piece of information. Embeddings work with text, images, audio, and other types of data. These numerical representations aka vectors create a representation of information in 3D space where closeness of points or clustering can indicate a relationship and meaning with respect to other piece of information. -
Layers
Layers allow the models to remember by helping build on each other's context. Each layer takes the input and a hidden state, to produce an output and also modify the hidden state. Each layer hence refines understanding of each token based on all others, allowing for building context with respect to each other.
The Transformer Model
Now that we have an understanding of LLMs, let's dive deeper into the Transformer architecture. Like RNNs,
Transformers are designed to process sequential data such as text. However, unlike RNNs, which handle data one
step at a time, Transformers use self-attention, which is a technique where each word in a sentence looks at all
the other words to understand its meaning in context.
The architecture and components
Transformer has two key parts:
- An Encoder - Encoder is the kind of like the reader part responsible for understanding relationships and analysing. This enables stronger comprehension of the problem/task at hand.
- A Decoder - Decoder is the storyteller part. Its key responsibility is to understand and predict the next word. In doing so, it generates content.
There are some variants of the architecture when it comes to models available. These are:
- Encoder-only models such as the popular model BERT are great at forming understanding of the text. Encoder-only models have bidirectional attention (aka full self-attention) which means the token under the lens is looked at with respect to all other tokens - both preceding and succeeding.
- Decoder-only models (also called autoregressive models) such as all the GPTs models, and the DeepSeek models are specialised in text-generation skills. These models have casual attention, which means the token under the lens is looked at with respect to all preceding tokens only.
- Encoder-Decoder models such as popular model T5 from Google allow for superior text-generation which incorporates deep understanding of encoder output. This leads to a well-grounded text-generation. These models have cross-attention, which means the token in the decoder sequence attends to tokens from the encoder sequence.
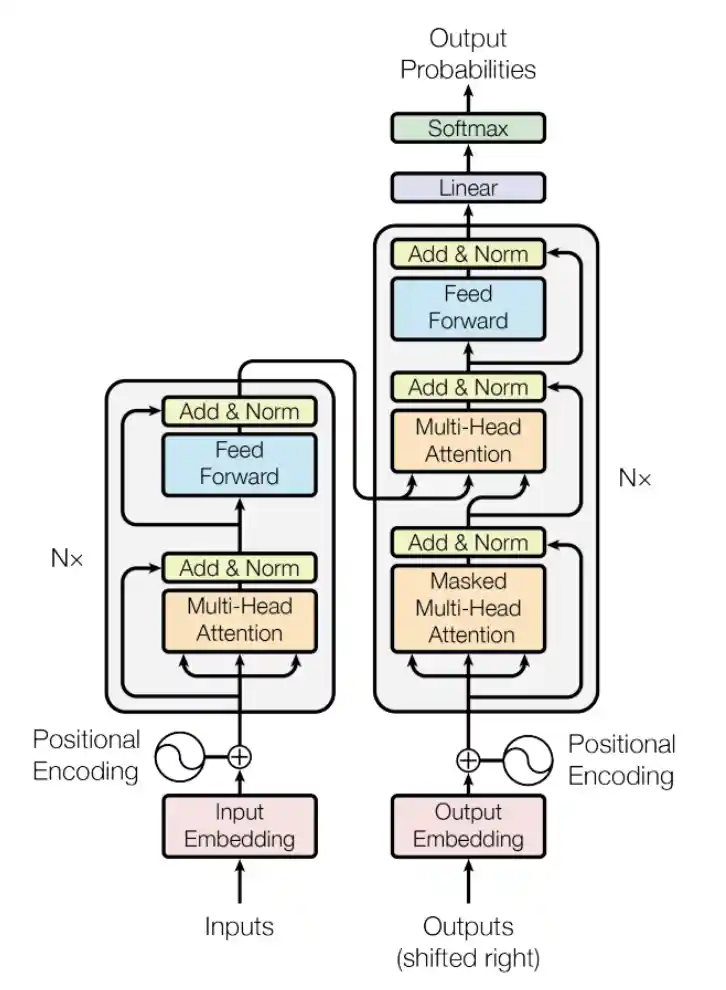 Referenced from Attention Is All You Need
[2]
Referenced from Attention Is All You Need
[2]
Stages to get ready!
LLM goes through 3 stages: pre-training, find-tuning, and prompting.
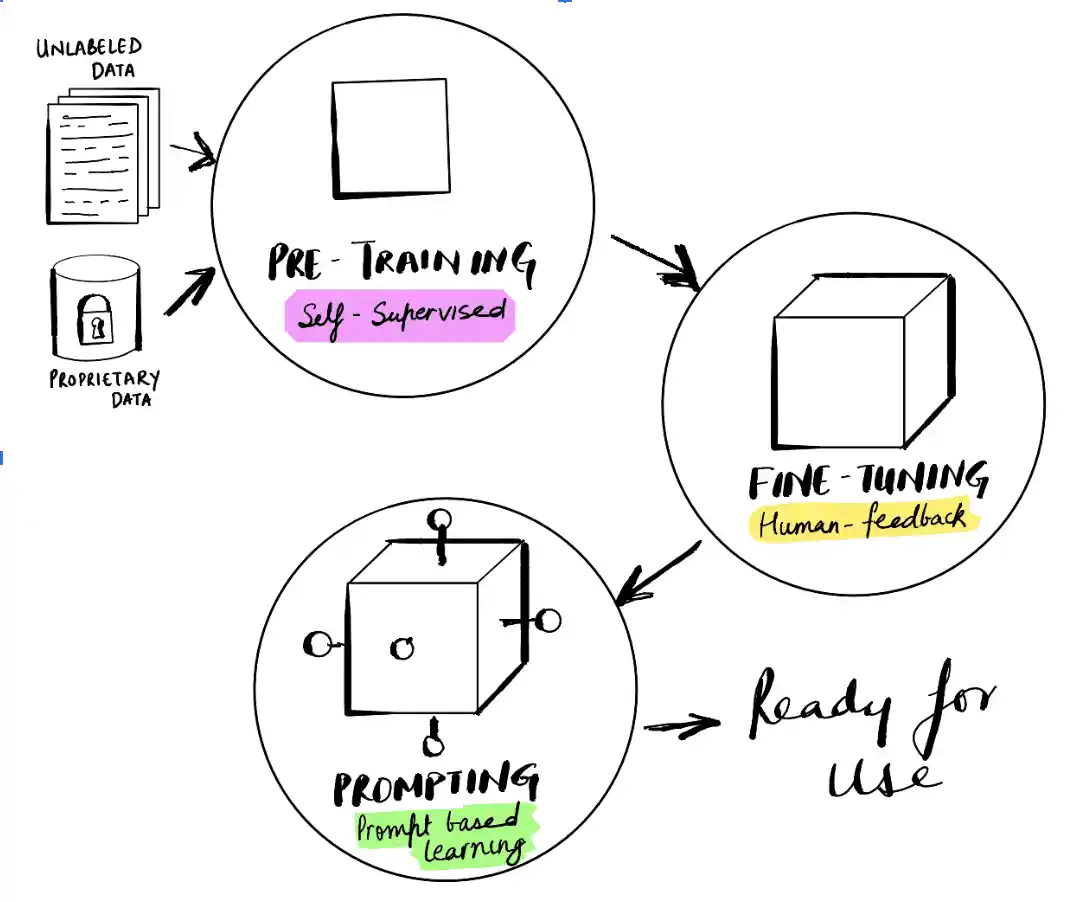
- Pre-training - This stage feeds massive amounts of data for the base model to develop understanding of general language and recognise patterns. This stage does not have human intervention or oversight, the model learns unsupervised. At this stage, the model's parameters start getting adjusted. The parameters play a vital role in the output produced by the language. For instance, T5, which is an encoder-decoder transformer, has parameter size ranging from 60M to 11B. This produced a general purpose model with broad base knowledge.
- Fine-Tuning - This stage takes in the model trained with broad-set knowledge and now trains it for more specific tasks e.g., summarisation, chatbot, categorisation, etc. This stage is often supervised by using known input-output pairs or reinforcement learning based on human feedback. This leads to parameters getting adjusted further. As a result, now we have a fine-tuned model with certain strengthened capabilities.
- Prompting - This is done to put the ready model to test. Direct prompts (i.e., where there are straight-forward questions) and indirect prompts (i.e., where models use a pattern or example to infer the question) are used to get the model to perform its task. This is where the model is frozen, and we are not changing the parameters any further. The key focus is to unlock reasoning, structure, and personality when exposed to inputs.
Other Important Buzzwords
Retrieval-Augmented Generation aka RAG
RAG is a technique which combines external data retrieval with LLMs to generate domain-specific, grounded,
up-to-date answers. Examples - Customer Support related chatbots which are provided product information from an
authoritative data source, Research-based search+summarise use cases, etc.
Prompt-Engineering
Prompt engineering is the process of crafting and structuring your prompt for GenAI models to get the desired
outcomes. A longer statement including context and/or more specific commands can help direct the underlying
model better.
Agentic AI or Agents
Agentic AI uses sophisticated reasoning and iterative planning to autonomously solve complex, multistep
problems. Unlike traditional LLM interactions, which is usually a single step input to output interaction,
Agents are capable of taking input and spanning their actions to multiple steps. These steps can involve
planning, invoking APIs & functions, iterating on intermediate results and delivering final output.
This is just laying the foundation right, and we have just dipped our toes in the water.
Read the next blog in the
series where we will look at the available tools, platforms and communities to further familiarise ourselves
with what is out there.
Checkout the Uncovering GenAI series all the following posts in this series.