Chaos Engineering — Driving Enterprise Adoption
Posted on 2021-02-09
- So you want us to break things on purpose?
- You expect us to run this in production?
- We have lots of pressing issues this is not a priority!
- How is this different from DR testing? ...
I was an engineering lead for a team that offered an internal chaos engineering framework for the firm. Whenever
we talked to application development teams, about getting started on chaos engineering for their products, above
listed were some common questions and concerns they voiced. To bridge this gap of understanding we needed
a path to drive enterprise-wide education and adoption for the practice. Our team brainstormed and came with
four pillars which we could leverage to ingrain this practice as BAU (business as usual) for teams.
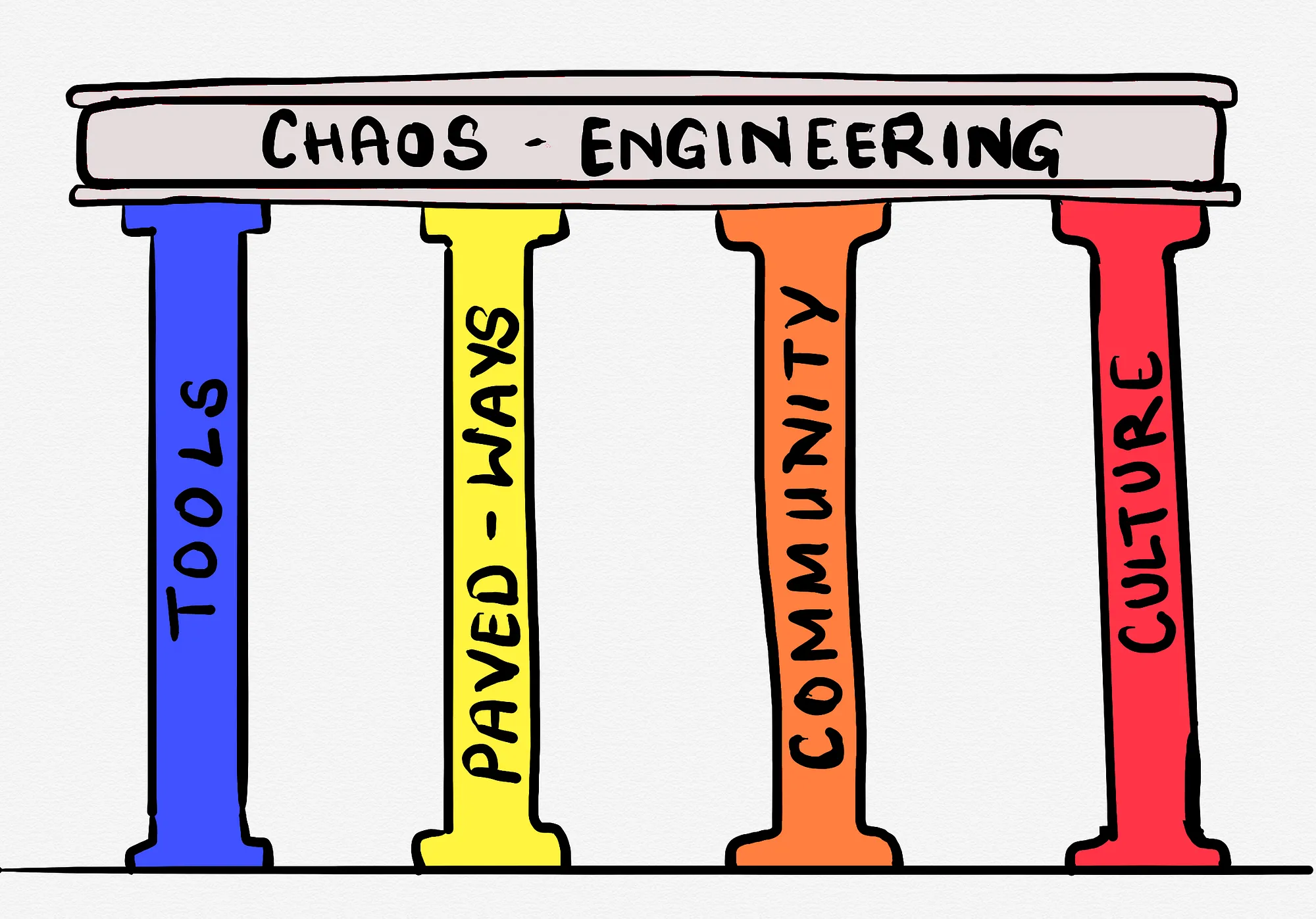
Tools
We built a framework for teams to create and execute their chaos experiments. This software tooling and
automation extensively leveraged open source libraries and encouraged contributions. Furthermore, the
architecture for the framework implicitly limited blast radius, making teams feel safe as they embarked on their
adoption journey. Features such as audit trail, logging, reporting, and credit-points further enhanced the
appeal for the product.
Paved Ways
Next, we focused on creating guided paths. The biggest barrier to get started is the fear of unknown. Hence, we
started with laying down a path which can guide teams and provide feedback as they go along. The aim was to help
teams to lower their armour and start adopting chaos engineering. This is what our paved paths looked like:
- Educate & Learn: The biggest barrier to get started is the fear of unknown. Hence, we started with providing the bundle of resources to get started. This included simple hello-world tutorials, sandbox environments, specific failure scenarios (e.g. database failure, Kafka failures). Furthermore, we set up many labs in internal meet-ups where people tried our tooling on the sandbox environment.
-
First Chaos Experiment:
As people climbed the first step in the ladder the next step was — "What should be there first chaos
experiment". Here is a perfect write-up to answer this question from Gremlin -
Chaos Engineering: the history, principles, and practice
.
Here is a quick summary:
- Lower Environments: Like most deployment pipelines we encourage teams to run it in their lower environment first, and gain confidence. As you climb up the confidence ladder then try in higher environments.
- Automated & Continuous: Running chaos experiments as part of automated pipelines or scheduled jobs continuously is the next step. Every time you run chaos experiments it is a unique run i.e. your system might have different loads, maybe some batch jobs are running at one time not the other, etc. Hence, running continuously exponentially increases the confidence in the system.
- Production: You must run the chaos experiments in production — the real environment, with real configuration and most importantly the REAL USERS. We DO NOT recommend doing so if you do not have observability around your system/product. You can only measure the impact of a failure and learn if you can observe your systems.
Community
My mentor once told me - "a scalable way to grow a product without having to be the bottleneck to answer all
customer queries is to create a self-sustained community around it". We started fostering an internal chaos
community. Here we leveraged many forums to bring the early adopters and the mass market community to ask
questions and share their experiences. We had a chat channel, a distribution list, and a monthly customer
advisory board meeting.
Culture
End of the day the idea behind driving this practice is to bring upon a mindset change from — "my changes work"
to "my product is resilient". That is, to make "resiliency", "high availability", "graceful degradation",
"disaster recovery" as NFRs (non-functional requirements) everybody's concern (developers, ops, and business
i.e. all stakeholders).
Key Take-away
Like most engineering practices embedding chaos engineering in your organization's culture will take time.
Ensure you provide tools, support and community to your teams to learn, and adopt the practice right